阿里云DashScope灵积模型服务通过标准化的API提供模型推理、模型微调训练等多种模型服务,本文通过调用DashScope中的通用文本向量模型,将业务数据向量化并在阿里云Elasticsearch(简称ES)中使用kNN实现检索。
前提条件
创建阿里云ES实例,本文以8.9版本为例。具体操作,请参见创建阿里云Elasticsearch实例。
创建ECS实例。具体操作,请参见自定义购买实例。
已开通灵积服务并获取API-KEY。具体操作,请参见:开通DashScope并创建API-KEY。
已开通DashVector向量检索服务,并获得API-KEY。具体操作,请参见:API-KEY管理。
已安装最新版SDK:安装DashScope SDK。
操作步骤
在ECS中执行如下命令,设置灵积的API-KEY。
export DASHSCOPE_API_KEY=YOUR_DASHSCOPE_API_KEY下载测试数据源,请单击extracted_data.json。
在ES的Kibana中执行如下命令创建索引。
PUT lingji_test { "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1 } }, "mappings": { "properties": { "context_vector": { "type": "dense_vector", "dims": 1536, "index": true, "similarity": "l2_norm" }, "context": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }context_vector向量部分参数说明,更详细说明,请参见dense-vector。参数 说明 type 用来存储浮点数的密集向量。需要设置为dense_vector。 dims 向量的维度大小。当index为true时,不能超过1024;当index为false时,不能超过2048 。 index 是否为kNN生成新的索引。实现近似kNN查询时,需要将index设置为true,默认为false。 similarity 文档间的相似度算法。index为true时,此值必须设置。可选值: - l2_norm:计算向量间欧式距离。_score公式:
1 / (1 + l2_norm(query, vector)^2)。 - dot_product:计算两个向量点积,_score计算依赖element_type参数值。
- element_type为float,所有向量需归一化为单位长度。_score公式:
(1 + dot_product(query, vector)) / 2。 - element_type为byte,所有向量需要有相同的长度,否则结果不准确。_score公式:
0.5 + (dot_product(query, vector) / (32768 * dims))。
- element_type为float,所有向量需归一化为单位长度。_score公式:
- cosine:计算向量间的余弦相似度。最有效的cosine使用方式是将所有向量归一化为单位长度代替dot_product。_score公式:
(1 + cosine(query, vector)) / 2。重要 余弦相似度算法不允许向量数据为0。
- l2_norm:计算向量间欧式距离。_score公式:
导入数据。
在ECS的Python3环境中调用DashScope SDK使用通用文本向量模型(通义实验室基于LLM底座的多语言文本统一向量模型),测试脚本示例如下。更多信息,请参见通用文本向量。
from elasticsearch import Elasticsearch from http import HTTPStatus import dashscope import certifi import json HOST = 'http://es-cn-g4t3l1ke60002****.public.elasticsearch.aliyuncs.com:9200' USERNAME = 'elastic' PASSWORD = '******' INDEX = "lingji_test" FILE_PATH = '/root/extracted_data.json' # 连接阿里云elasticsearch es = Elasticsearch(HOST, basic_auth = (USERNAME, PASSWORD)) # 灵积文本转向量,模型为text_embedding_v1 def embed_with_str(text): resp = dashscope.TextEmbedding.call( model=dashscope.TextEmbedding.Models.text_embedding_v1, input=text) vector_data = resp["output"]["embeddings"][0]["embedding"] return vector_data # 加载本地文件路径 with open(FILE_PATH, 'r', encoding='utf-8') as file: data = json.load(file) # 上传文档到elasticsearch for doc in data: # 源数据中需要转成向量的字段数据,以实际为准 doc["context_vector"] = embed_with_str(doc["context"]) response = es.index(index=INDEX, document=doc) print(response)部分参数说明:
参数
说明
HOST
阿里云ES实例的域名和端口。示例:http://es-cn-xxxxxx.public.elasticsearch.aliyuncs.com:9200。
USERNAME
阿里云ES实例的用户名。
PASSWORD
阿里云ES实例的密码。
INDEX
创建的索引名。
FILE_PATH
源数据在ECS中的路径。
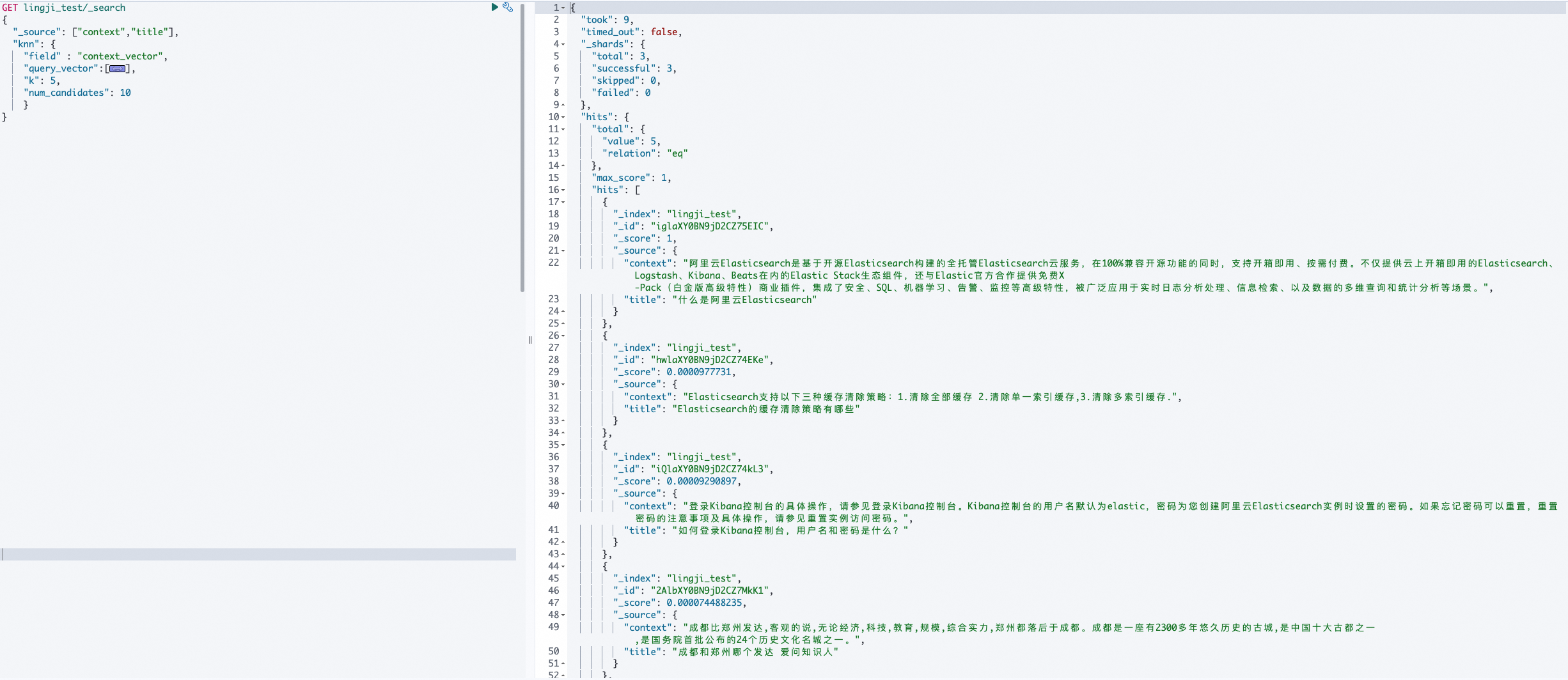
在ES的Kibana中执行以下命令查询索引中的数据。
GET lingji_test/_search { "_source": ["context","title"], "knn": { "query_vector":[], "k": 5, "num_candidates": 10 } }根据查询结果可知实现了文本数据向量化。
反馈
- 本页导读 (1)
文档反馈